This two-part series is a gentle, high-level introduction to offline web development. In Part 1 we got a basic service worker running, which caches our application resources. Now let’s extend it to support offline.
Article Series:
- The Setup
- The Implementation (you are here!)
Making an `offline.htm` file
Next, lets add some code to detect when the application is offline, and if so, redirect our users to a (cached) `offline.htm`.
But wait, if the service worker file is generated automatically, how do we go about adding in our own code, manually? Well, we can add an entry for importScripts, which tells our service worker to import the scripts we specify. It does this through the service worker’s native importScripts function, which is well-named. And we’ll also add our `offline.htm` file to our statically cached list of files. The new files are highlighted below:
new SWPrecacheWebpackPlugin({
mergeStaticsConfig: true,
filename: "service-worker.js",
importScripts: ["../sw-manual.js"],
staticFileGlobs: [
//...
"offline.htm"
],
// the rest of the config is unchanged
})Now, let’s go in our `sw-manual.js` file, and add code to load the cached `offline.htm` file when the user is offline.
toolbox.router.get(/books$/, handleMain);
toolbox.router.get(/subjects$/, handleMain);
toolbox.router.get(/localhost:3000\/$/, handleMain);
toolbox.router.get(/mylibrary.io$/, handleMain);
function handleMain(request) {
return fetch(request).catch(() => {
return caches.match("react-redux/offline.htm", { ignoreSearch: true });
});
}We’ll use the toolbox.router object we saw before to catch all our top-level routes, and if the main page doesn’t load from the network, send back the (hopefully cached) `offline.htm` file.
This is one of the few times in this post you’ll see promises being used directly, instead of with the async syntax, mainly because in this case it’s actually easier to just tack on a .catch(), rather than set up a try{} catch{} block.
The `offline.htm` file will be pretty basic, just some HTML that reads cached books from IndexedDB, and displays them in a rudimentary table. But before showing that, let’s walk through how to actually use IndexedDB (if you want to just see it now, it’s here)
Hello World, IndexedDB
IndexedDB is an in-browser database. It’s ideal for enabling offline functionality since it can be accessed without network connectivity, but it’s by no means limited to that.
The API pre-dates Promises, so it’s callback based. We’ll go through everything with the native API, but in practice, you’ll likely want to wrap and simplify it, either with your own helper methods which wrap the functionality with Promises, or with a third-party utility.
Let me repeat: the API for IndexedDB is awful. Here’s Jake Archibald saying he wouldn’t even teach it directly
I always teach the underlying API rather than an abstraction, but I'd make an exception for IDB.
— Jake Archibald (@jaffathecake) December 2, 2017
We’ll still go over it because I really want you to see everything as it is, but please don’t let it scare you away. There’s plenty of simplifying abstractions out there, for example dexie and idb.
Setting up our database
Let’s add code to sw-manual that subscribes to the service worker’s activate event, and checks to see if we already have an IndexedDB setup; if not, we’ll create, and then fill it with data.
First, the creating bit.
self.addEventListener("activate", () => {
//1 is the version of IDB we're opening
let open = indexedDB.open("books", 1);
//should only be called the first time, when version 1 does not exist
open.onupgradeneeded = evt => {
let db = open.result;
//this callback should only ever be called upon creation of our IDB, when an upgrade is needed
//for version 1, but to be doubly safe, and also to demonstrade this, we'll check to see
//if the stores exist
if (!db.objectStoreNames.contains("books") || !db.objectStoreNames.contains("syncInfo")) {
if (!db.objectStoreNames.contains("books")) {
let bookStore = db.createObjectStore("books", { keyPath: "_id" });
bookStore.createIndex("imgSync", "imgSync", { unique: false });
}
if (!db.objectStoreNames.contains("syncInfo")) {
db.createObjectStore("syncInfo", { keyPath: "id" });
evt.target.transaction
.objectStore("syncInfo")
.add({ id: 1, lastImgSync: null, lastImgSyncStarted: null, lastLoadStarted: +new Date(), lastLoad: null });
}
evt.target.transaction.oncomplete = fullSync;
}
};
});The code’s messy and manual; as I said, you’ll likely want to add some abstractions in practice. Some of the key points: we check for the objectStores (tables) we’ll be using, and create them as needed. Note that we can even create indexes, which we can see on the books store, with the imgSync index. We also create a syncInfo store (table) which we’ll use to store information on when we last synced our data, so we don’t pester our servers too frequently, asking for updates.
When the transaction has completed, at the very bottom, we call the fullSync method, which loads all our data. Let’s see what that looks like.
Performing an initial sync
Below is the relevant portion of the syncing code, which makes repeated calls to our endpoint to load our books, page by page, adding each result to IDB along the way. Again, this is using zero abstractions, so expect a lot of bloat.
See this GitHub gist for the full code, which includes some additional error handling, and code which runs when the last page is finished.
function fullSyncPage(db, page) {
let pageSize = 50;
doFetch("/book/offlineSync", { page, pageSize })
.then(resp => resp.json())
.then(resp => {
if (!resp.books) return;
let books = resp.books;
let i = 0;
putNext();
function putNext() { //callback for an insertion, with indicators it hasn't had images cached yet
if (i < pageSize) {
let book = books[i++];
let transaction = db.transaction("books", "readwrite");
let booksStore = transaction.objectStore("books");
//extend the book with the imgSync indicated, add it, and on success, do this for the next book
booksStore.add(Object.assign(book, { imgSync: 0 })).onsuccess = putNext;
} else {
//either load the next page, or call loadDone()
}
}
});
}The putNext() function is where the real work is done. This serves as the callback for each successful insertion’s success. In real life we’d hopefully have a nice method that adds each book, wrapped in a promise, so we could do a simple for of loop, and await each insertion. But this is the “vanilla” solution or at least one of them.
We modify each book before inserting it, to set the imgSync property to 0, to indicate that this book has not had its image cached, yet.
And after we’ve exhausted the last page, and there are no more results, we call loadDone(), to set some metadata indicating the last time we did a full data sync.
In real life, this would be a good time to sync all those images, but let’s instead do it on-demand by the web app itself, in order to demonstrate another feature of service workers.
Communicating between the web app, and service worker
Let’s just pretend it would be a good idea to have the books’ covers load the next time the user visits our page when the service worker is running. Let’s have our web app send a message to the service worker, and we’ll have the service worker receive it, and then sync the book covers.
From our app code, we attempt to send a message to a running service worker, instructing it to sync images.
In the web app:
if ("serviceWorker" in navigator) {
try {
navigator.serviceWorker.controller.postMessage({ command: "sync-images" });
} catch (er) {}
}In `sw-manual.js`:
self.addEventListener("message", evt => {
if (evt.data && evt.data.command == "sync-images") {
let open = indexedDB.open("books", 1);
open.onsuccess = evt => {
let db = open.result;
if (db.objectStoreNames.contains("books")) {
syncImages(db);
}
};
}
});In sw-manual we have code to catch that message, and call the syncImages() method. Let’s look at that, next.
function syncImages(db) {
let tran = db.transaction("books");
let booksStore = tran.objectStore("books");
let idx = booksStore.index("imgSync");
let booksCursor = idx.openCursor(0);
let booksToUpdate = [];
//a cursor's onsuccess callback will fire for EACH item that's read from it
booksCursor.onsuccess = evt => {
let cursor = evt.target.result;
//if (!cursor) means the cursor has been exhausted; there are no more results
if (!cursor) return runIt();
let book = cursor.value;
booksToUpdate.push({ _id: book._id, smallImage: book.smallImage });
//read the next item from the cursor
cursor.continue();
};
async function runIt() {
if (!booksToUpdate.length) return;
for (let book of booksToUpdate) {
try {
//fetch, and cache the book's image
await preCacheBookImage(book);
let tran = db.transaction("books", "readwrite");
let booksStore = tran.objectStore("books");
//now save the updated book - we'll wrap the IDB callback-based opertion in
//a manual promise, so we can await it
await new Promise(res => {
let req = booksStore.get(book._id);
req.onsuccess = ({ target: { result: bookToUpdate } }) => {
bookToUpdate.imgSync = 1;
booksStore.put(bookToUpdate);
res();
};
req.onerror = () => res();
});
} catch (er) {
console.log("ERROR", er);
}
}
}
}We’re cracking open the imageSync index from before, and reading all books that have a zero, which means they haven’t had their images sync’d yet. The booksCursor.onsuccess will be called over and over again, until there are no books left; I’m using this to put them all into an array, at which point I call the runIt() method, which runs through them, calling preCacheBookImage() for each. This method will cache the image, and if there are no unforeseen errors, update the book in IDB to indicate that imgSync is now 1.
If you’re wondering why in the world I’m going through the trouble to save all the books from the cursor into an array, before calling runIt(), rather than just walking through the results of the cursor, and caching and updating as I go, well — it turns out transactions in IndexedDB are a bit weird. They complete when you yield to the event loop unless you yield to the event loop in a method provided by the transaction. So if we leave the event loop to go do other things, like make a network request to pull down an image, then the cursor’s transaction will complete, and we’ll get an error if we try to continue reading from it later.
Manually updating the cache.
Let’s wrap this up, and look at the preCacheBookImage method which actually pulls down a cover image, and adds it to the relevant cache, (but only if it’s not there already.)
async function preCacheBookImage(book) {
let smallImage = book.smallImage;
if (!smallImage) return;
let cachedImage = await caches.match(smallImage);
if (cachedImage) return;
if (/https:\/\/s3.amazonaws.com\/my-library-cover-uploads/.test(smallImage)) {
let cache = await caches.open("local-images1");
let img = await fetch(smallImage, { mode: "no-cors" });
await cache.put(smallImage, img);
}
}If the book has no image, we’re done. Next, we check if it’s cached already — if so, we’re done. Lastly, we inspect the URL, and figure out which cache it belongs in.
The local-images1 cache name is the same from before, which we set up in our dynamic cache. If the image in question isn’t already there, we fetch it, and add it to cache. Each cache operation returns a promise, so the async/await syntax simplifies things nicely.
Testing it out
The way it’s set up, if we clear our service worker either in dev tools, below, or by just opening a fresh incognito window…

…then the first time we view our app, all our books will get saved to IndexedDB.

When we refresh, the image sync will happen. So if we start on a page that’s already pulling down these images, we’ll see our normal service worker saving them to cache (ahem, assuming we delay the ajax call to give our Service Worker a chance to install), which is what these events are in our network tab.

Then, if we navigate elsewhere and refresh, we won’t see any network requests for those image, since our sync method is already finding everything in cache.
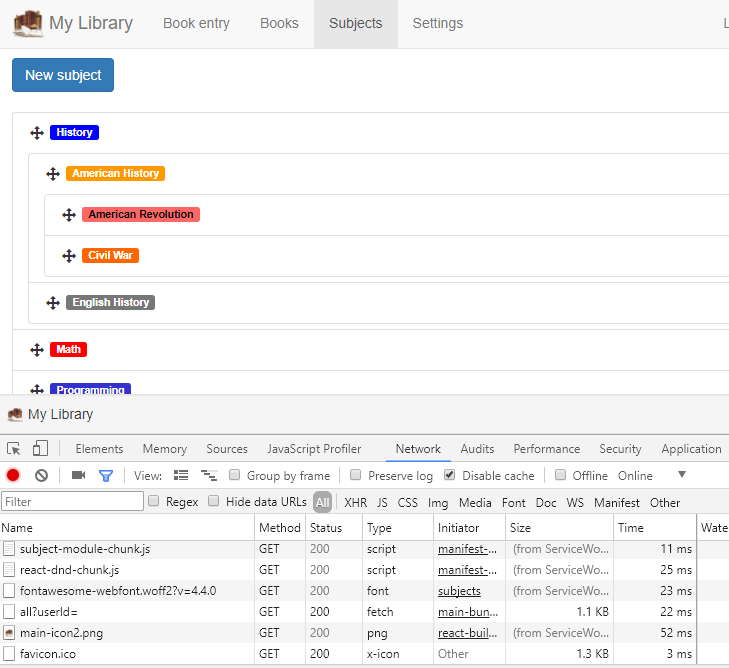
If we clear our service workers again, and start on this same page, which is not otherwise pulling these images down, then refresh, we’ll see the network requests to pull down, and sync these images to cache.

Then if we navigate back to the page that uses these images, we won’t see the calls to cache these images, since they’re already cached; moreover, we’ll see these images being retrieved from cache by the service worker.

Both our runtimeCaching provided by sw-toolbox, and our own manual code are working together, off of the same cache.
It works!
As promised, here’s the `offline.htm` page
<div style="padding: 15px">
<h1>Offline</h1>
<table class="table table-condescend table-striped">
<thead>
<tr>
<th></th>
<th>Title</th>
<th>Author</th>
</tr>
</thead>
<tbody id="booksTarget">
<!--insertion will happen here-->
</tbody>
</table>
</div>let open = indexedDB.open("books");
open.onsuccess = evt => {
let db = open.result;
let transaction = db.transaction("books", "readonly");
let booksStore = transaction.objectStore("books");
var request = booksStore.openCursor();
let rows = ``;
request.onsuccess = function(event) {
var cursor = event.target.result;
if(cursor) {
let book = cursor.value;
rows += `
<tr>
<td><img src="${book.smallImage}" /></td>
<td>${book.title}</td>
<td>${Array.isArray(book.authors) ? book.authors.join("<br/>") : book.authors}</td>
</tr>`;
cursor.continue();
} else {
document.getElementById("booksTarget").innerHTML = rows;
}
};
}Now let’s tell Chrome to pretend to be offline, and test it out:

Cool!
Where to, from here?
We’re barely scratching the surface. Your users can update these data from multiple devices, and each one will need to keep in sync somehow. You could either periodically wipe your IDB tables and re-sync; have the user manually trigger a re-sync when they want; or you could get really ambitious and try to log all your mutations on your server, and have each service worker on each device request all changes that happened since the last time it ran, in order to sync up.
The most interesting solution here is PouchDB, which does this syncing for you; the catch is it’s designed to work with CouchDB, which you may or may not be using.
Syncing local changes
For one last piece of code, let’s consider an easier problem to solve: syncing your IndexedDB with changes that are made right this minute, by your user who’s using your web app. We can already intercept fetch requests in the service worker, so it should be easy to listen for the right mutation endpoint, run it, then then peak at the results and update IndexedDB accordingly. Let’s take a look.
toolbox.router.post(/graphql/, request => {
//just run the request as is
return fetch(request).then(response => {
//clone it by necessity
let respClone = response.clone();
//do this later - get the response back to our user NOW
setTimeout(() => {
respClone.json().then(resp => {
//this graphQL endpoint is for lots of things - inspect the data response to see
//which operation we just ran
if (resp && resp.data && resp.data.updateBook && resp.data.updateBook.Book) {
syncBook(resp.data.updateBook.Book);
}
}, 5);
});
//return the response to our user NOW, before the IDB syncing
return response;
});
});
function syncBook(book) {
let open = indexedDB.open("books", 1);
open.onsuccess = evt => {
let db = open.result;
if (db.objectStoreNames.contains("books")) {
let tran = db.transaction("books", "readwrite");
let booksStore = tran.objectStore("books");
booksStore.get(book._id).onsuccess = ({ target: { result: bookToUpdate } }) => {
//update the book with the new values
["title", "authors", "isbn"].forEach(prop => (bookToUpdate[prop] = book[prop]));
//and save it
booksStore.put(bookToUpdate);
};
}
};
}This may seem a bit more involved than you were hoping. We can only read the fetch response once, and our application thread will also need to read it, so we’ll first clone the response. Then, we’ll run a setTimeout() so we can return the original response to the web application/user as quickly as possible, and do what we need thereafter. Don’t just rely on the promise in respClone.json() to do this, since promises use microtasks. I’ll let Jake Archibald explain what exactly that means, but the short of it is that they can starve the main event loop. I’m not quite smart enough to be certain whether that applies here, so I just went with the safe approach of setTimeout.
Since I’m using GraphQL, the responses are in a predictable format, and it’s easy to see if I just performed the operation I’m interested in, and if so I can re-sync the affected data.
Further reading
Literally everything here is explained in wonderful depth in this book by Tal Ater. If you’re interested in learning more, you can’t beat that as a learning resource.
For some more immediate, quick resources, here’s an MDN article on IndexedDB, and a service workers introduction, and offline cookbook, both from Google.
Parting thoughts
Giving your user useful things to do with your web app when they don’t even have network connectivity is an amazing new ability web developers have. As you’ve seen though, it’s no easy task. Hopefully this post has given you a realistic idea of what to expect, and a decent introduction to the things you’ll need to do to accomplish this.
Article Series:
- The Setup
- The Implementation (you are here!)
can you share end result as github repo?
It’s in my booklist project linked in part 1. Most of the relevant service worker code can be found here, though
https://github.com/arackaf/booklist/blob/master/react-redux/sw-manual.js
Though much of it isn’t in use just yet, since I need to make some updates on my project to really do this right – but it was of course all tested and run when writing this piece.