Development is complicated. Our job is an ongoing battle between getting the job done and doing that job in a safe, long-lasting way.
Developers say things like, “I’m just going to do this quick and dirty first,” because it’s taken as fact that if you code anything quickly, it not only will be prone to mistakes, but that you’ll be deliberately not honoring established conventions and skipping tasks that make for more solid code.
There is probably no practical way to make it impossible to write sloppy, bad code, but it is fascinating to consider how tooling has evolved to make it harder.
Let’s get all Poka-yoke on development.
The obvious ones are automated code quality tools.
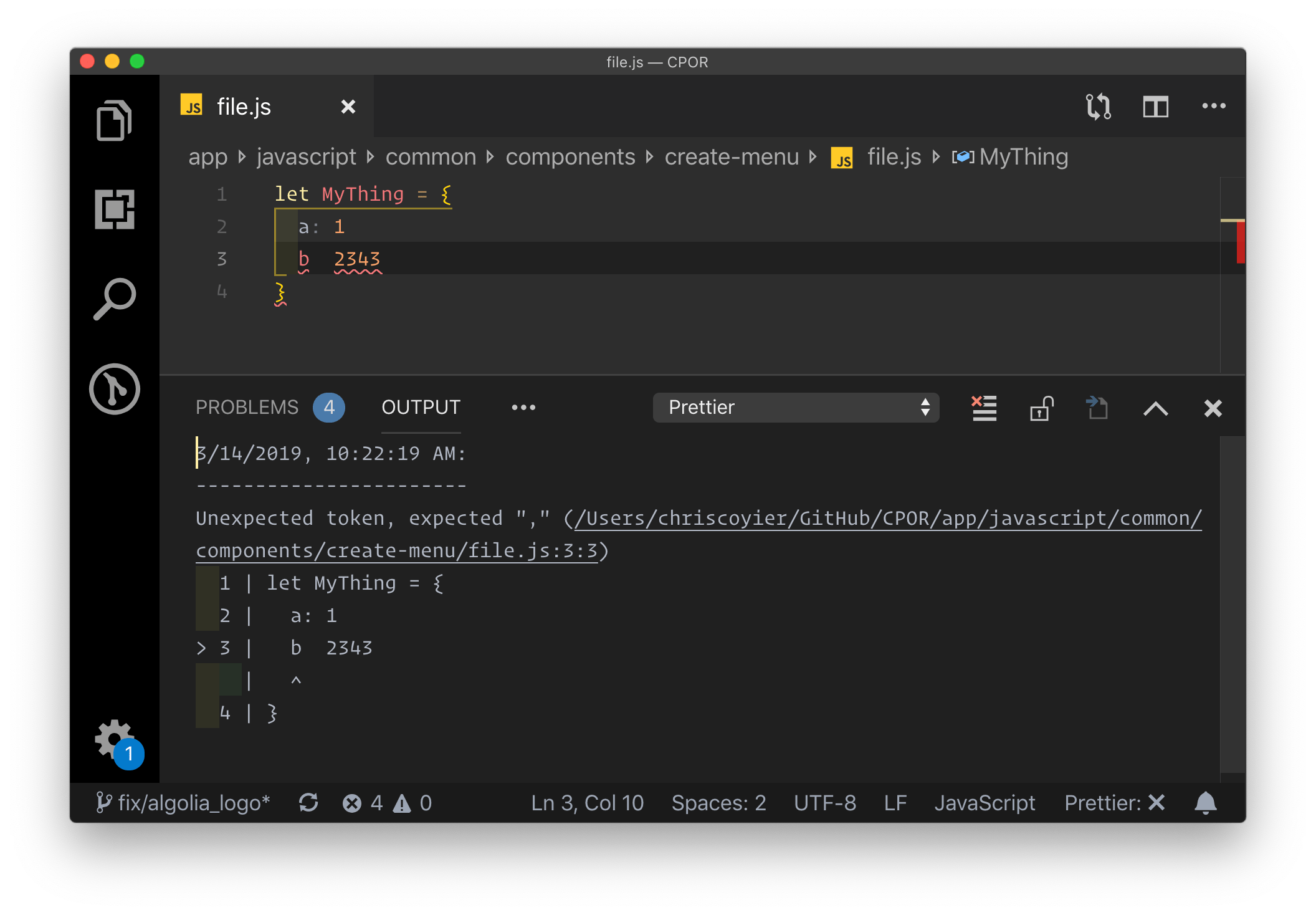
Say you’re writing JavaScript. ESLint is a mega-popular tool that looks at your code as you are writing it and lets you know about issues.

ESLint is configurable and those configurations can be enforced to a team’s liking. If you’d prefer to use some strong and established conventions, I believe the most popular out there is AirBnbs configuration.
There are alternatives to everything, of course. This post isn’t so much about a comprehensive tooling list as it is about considering the types of tools that help us push us toward writing better code. That said, stylelint is good for CSS, PHP_CodeSniffer is good for PHP, and Rubocop is good for Ruby.
Prettier is in a similar, but unique category. It is like a “beautifier” for your code, in that it helps you reformat it not only to look good but to follow team conventions (e.g. single quotes! Two space indentions!) as well. The most common way to use Prettier is that it runs as you save the file. So perhaps you write quickly and don’t worry about formatting as much, because it happens for you the second you save. There is an interesting side-benefit of quality here as Prettier can fail, and if it does, you have a problem in the syntax of your code you need to fix. Super useful.
I’m intrigued by tools like Sonarlint, Code Climate, and Resharper that look, to me, essentially like linters, but deliver only a best-practice analysis rather than configuring things yourself. It also claims to understand your code at a deeper level. Webhint and Deepscan look similarly interesting. Feel free to correct me if I have this wrong because I haven’t gotten a chance to use any of them yet.
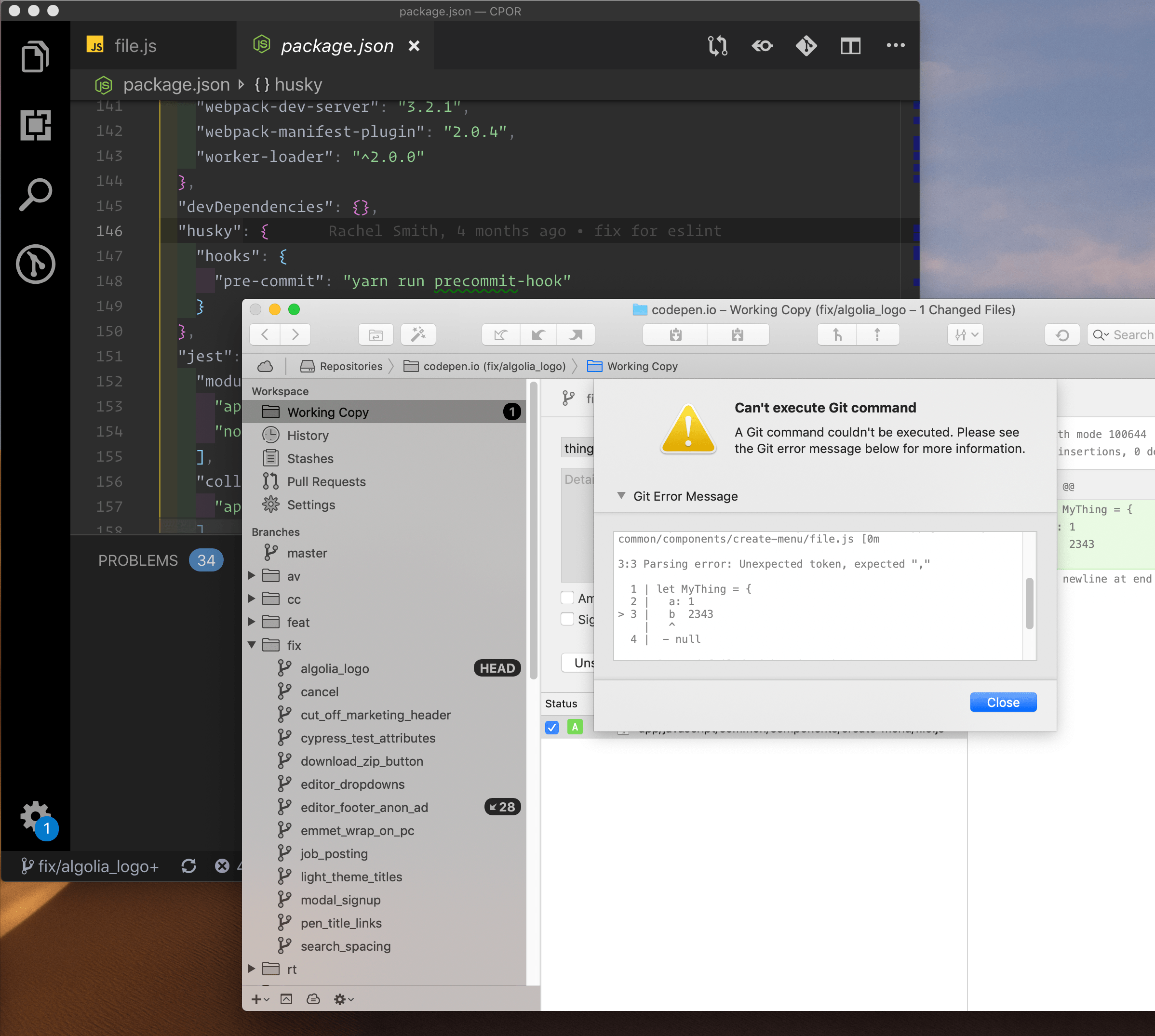
Taking linting a step further, you can make passing lint tests a requirement before files can even be committed into Git. Git hooks are the ticket here, and the most popular tool for managing them is Husky.
Similarly, actual tests are powerful preventers of bad code.
It’s always smart to write tests. Deploying code that breaks features is embarrassing, a waste of time, and can negatively impact your business. Yet we do it all too often. The whole point of tests is to prevent that.
Things like Jest for JavaScript and RSpec for Ruby are useful, and considered unit testing. It’s work! You manually write functions that expect certain results. I expect that if I call a function with these parameters it returns this value!

Test-Driven Development (TDD) is a practice in which you write the test before you write the actual code that does the thing you’re trying to do. It’s a nice way to work if you can pull it off, as you’ve got code coverage from the get-go.
Another type of automated testing is integration (also known as end-to-end) testing. I’m a fan of Cypress for that. It simulates a user actually using a browser. Go to this URL! Click this! Fill out this field and submit the form! Does this thing exist now? Is the URL what it’s supposed to be? Is this other thing visible? That kind of testing is powerful in that a lot of things have to be going right for these to pass, so there is a ton of implied testing.

As a CSS kinda guy, I’m also a fan of tests that watch to make sure the site looks how it’s supposed to look and there aren’t unintended consequences of styling changings. Percy is awesome for that (see our video).
And while we’re talking about all the different types of automated testing you can do, there are all sorts of tools to automate some level of accessibiilty testing. Plus, there are tools like Calibre and SpeedCurve that automate Lighthouse for watching performance.
Languages and language features that help us, wittingly or not
Take JSX, for example. It’s entirely possible to write bad HTML in JSX, but you can’t write broken HTML. The component will error out entirely and you’ll know as you’re working. That’s not even close to the reason JSX exists, but I find it an interesting side effect. I’ve fixed many bugs in my career that had to do with malformed HTML causing problems, ranging from tiny side effects to massive layout blunders.
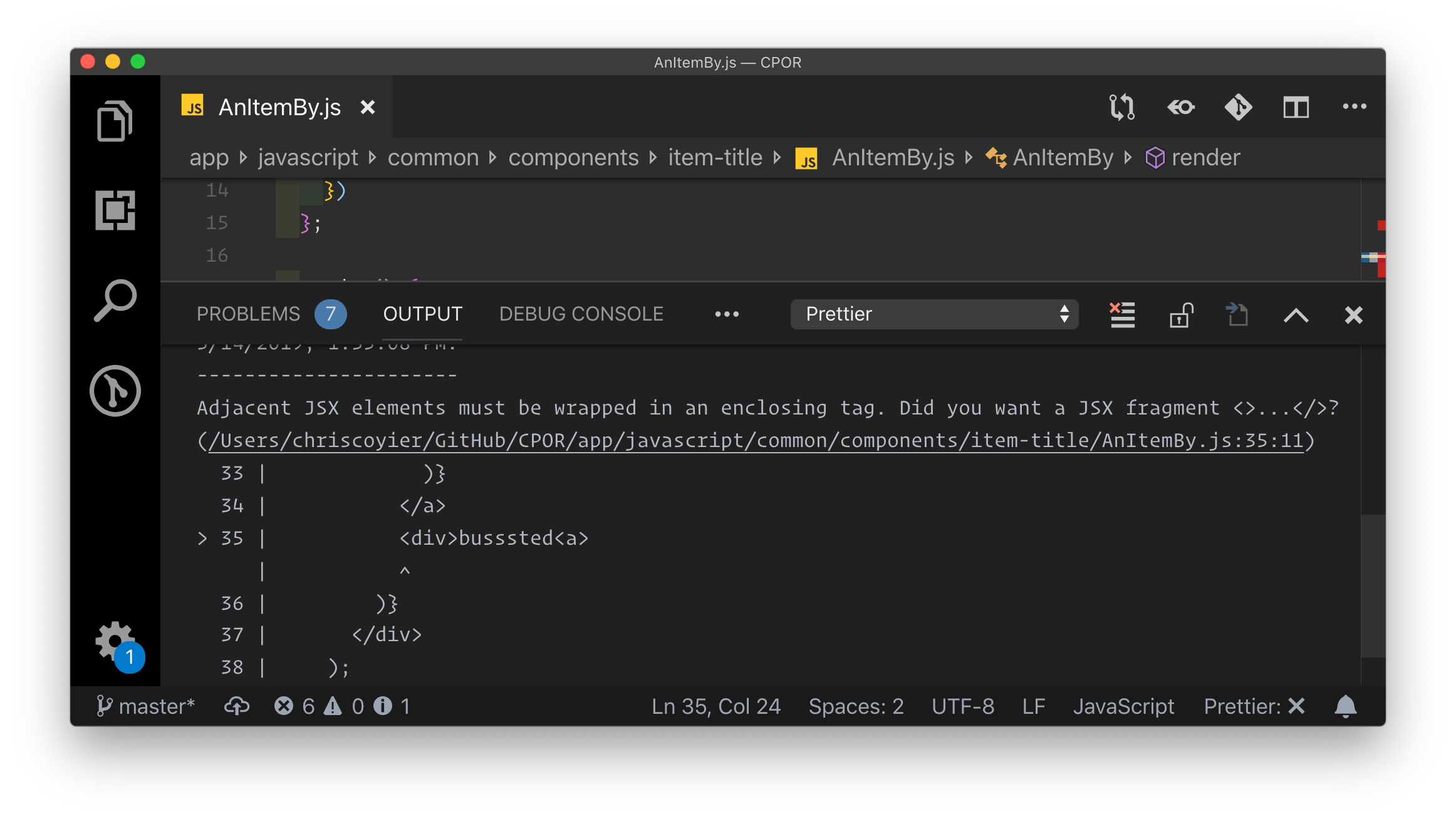
Similarly, a tool like Emmet can help generate valid HTML. I use Emmet all the time, and didn’t even think of that until it was mentioned to me.
I also think of React features, like PropTypes, that throw errors when missing or unexpected data is thrown at them. Not to mention you can configure your linter to yell at you if you’re missing the PropType. That’s pretty powerful testing to be enforced for a fairly small amount of labor (compared to, say, writing a test). You can even force them to help with accessibility.

It would be impossible to not mention TypeScript here. One of the major points of using TypeScript is code safety. The fact that it’s getting huge (listen to Laurie Voss on this) points to the fact that we want to enforce that safety. I remember when Angular 2 came out, there were long, solid explanations as to why. People also talk about the tooling improvements you get with TypeScript: advanced autocompletion, navigation, and refactoring. They are all, in a way, also about code safety — having the editor help you write correct file names and function names. TypeScript or not, any sort of autocomplete/IntelliSense is great to have.
The whole idea of this post came from me thinking about how GraphQL has this “you can’t screw it up” quality to it. You can’t ask for data that isn’t there, as it will error right as you’re working with it — and then you’ll fix it. And you can’t get back data that you aren’t expecting, as you’ve described exactly what you want back and that’s what GraphQL does. It’s not that you can’t write bad code that uses GraphQL or write a bad GraphQL implementation, but the technology sort of encourages better code and I’m fascinated by that.
CSS-in-JS, while that’s probably too broad a term generally, applies to this discussion. Most of the solutions on that spectrum involve some kind of style scoping, and style scoping provides this “you can’t screw it up” topic we’re focusing on. You can’t cause unintended side effects when the selector you’ve just written compiles to something you’ve never hand-written, like .SpecificComponent_root_34lkj4x.
Your co-workers are an awesome line of defense
First, give y’allselves a system. Nothing goes to the master branch directly, and everything has to be a Merge/Pull Request. That gives you a spot to talk about code quality — not to mention a place where you can run a suite of automated tests before the code is dangerously close to production.
GitLab has a concept of approvers for a Merge Request. You pick some people that have to approve the branch before it can be merged.
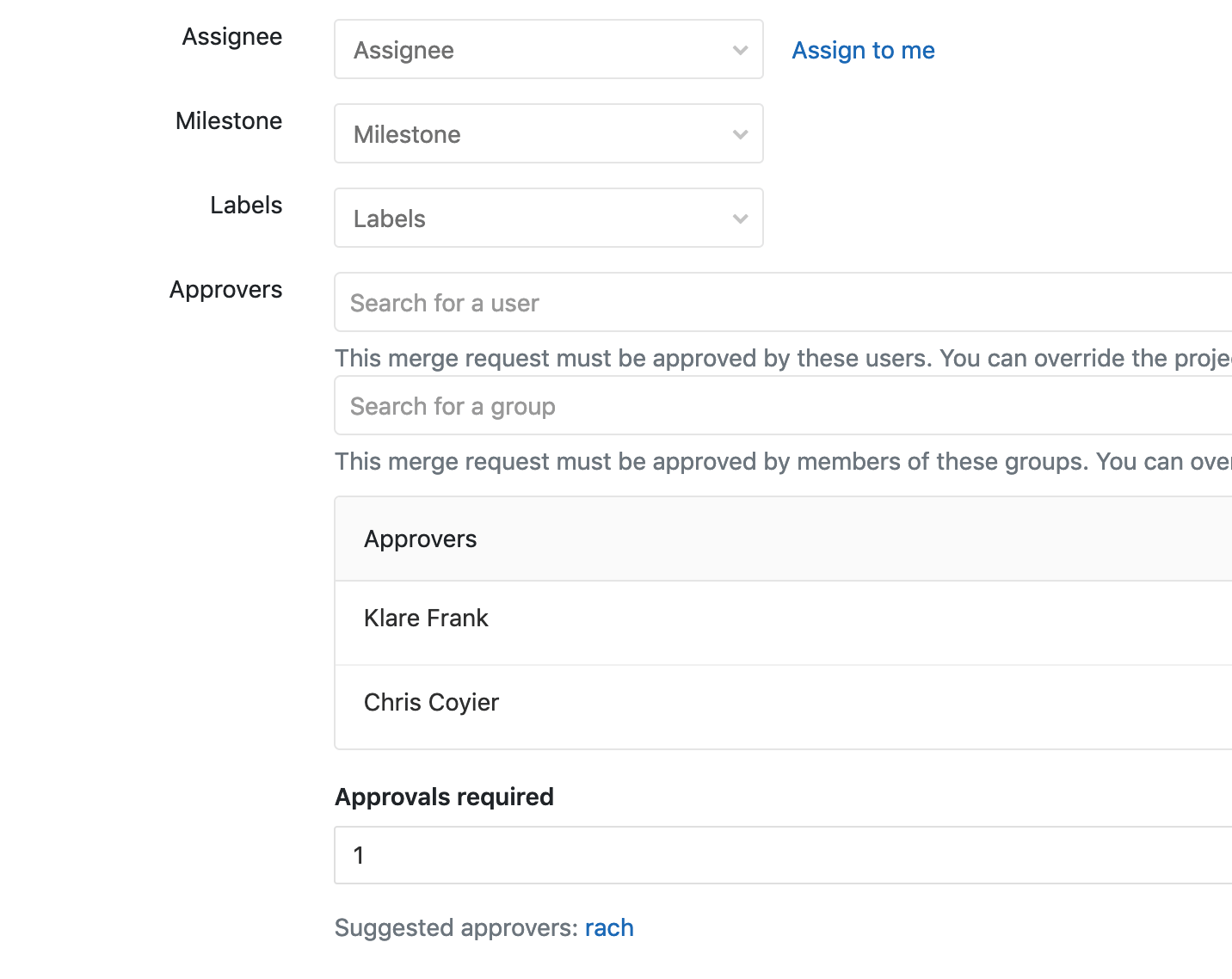
GitHub has the same concept with protected branches. Perhaps the best thing you can do to prevent bad code is to widen the responsibility. There is always a risk this just becomes a glance-at-the-code-for-two-seconds-and-give-it-a-👍 motion, but that’s on y’all to make sure reviews are taken seriously. I’ve seen lots of value in a requirement that many sets of eyeballs need to be on code before it goes out. “Given enough eyeballs, all bugs are shallow” and all that.
We’ll always be screwing up code, but we can also always be finding ways not to.
In addition to using StyleLint, you could use Constyble to lint CSS for increasing complexity. It will give results on a higher level than Stylelint based on selector complexity, average amount of selectors per rule, declarations per rule etc.
First of all, great post!
I recently joined a company where they have bought into GraphQL and you stoles the words out of my mouth with this paragraph:
What about sass? What are the best tool to lint, test?
@Israel:
We’re using
https://www.npmjs.com/package/stylelint
with
https://www.npmjs.com/package/stylelint-scss
Maybe also see https://stylelint.io/user-guide/css-processors/#parsing-non-standard-syntax