Chapter names in books, quotes from a speech, keywords in an article, stats on a report — these are all types of content that could be helpful to isolate and turn into a high-level summary of what’s important.
For example, have you seen the way Business Insider provides an article’s key points before getting into the content?
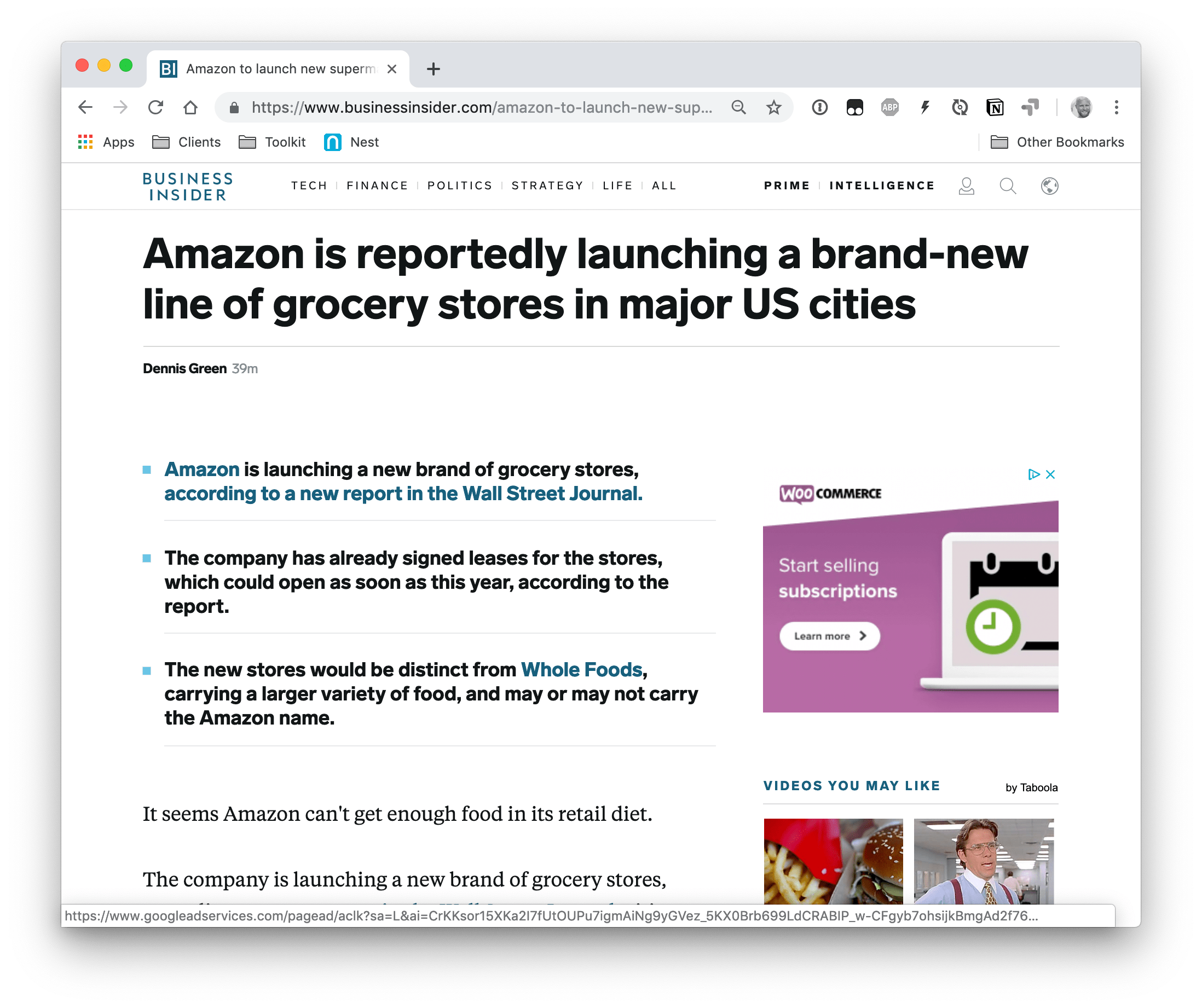
That’s the sort of thing we’re going to do, but try to extract the high points directly from the article using HTML Slot, HTML Template and Shadow DOM.
These three titular specifications are typically used as part of Web Components — fully functioning custom element modules meant to be reused in webpages.
Now, what we aim to do, i.e. text extraction, doesn’t need custom elements, but it can make use of those three technologies.
There is a more rudimentary approach to do this. For example, we could extract text and show the extracted text on a page with some basic script without utilizing slot and template. So why use them if we can go with something more familiar?
The reason is that using these technologies permits us a preset markup code (also optionally, style or script) for our extracted text in HTML. We’ll see that as we proceed with this article.
Now, as a very watered-down definition of the technologies we’ll be using, I’d say:
- A template is a set of markup that can be reused in a page.
- A slot is a placeholder spot for a designated element from the page.
- A shadow DOM is a DOM tree that doesn’t really exist on the page till we add it using script.
We’ll see them in a little more depth once we get into coding. For now, what we’re going to make is an article that follows with a list of key points from the text. And, you probably guessed it, those key points are extracted from the article text and compiled into the key points section.
See the Pen
Text Extraction with HTML Slot and HTML Template by Preethi Sam (@rpsthecoder)
on CodePen.
The key points are displayed as a list with a design in between the points. So, let’s first create a template for that list and designate a place for the list to go.
<article><!-- Article content --></article>
<!-- Section where the extracted keypoints will be displayed -->
<section id='keyPointsSection'>
<h2>Key Points:</h2>
<ul><!-- Extracted key points will go in here --></ul>
</section>
<!-- Template for the key points list -->
<template id='keyPointsTemplate'>
<li><slot name='keyPoints'></slot></li>
<li style="text-align: center;">⤙—⤚</li>
</template>What we’ve got is a semantic <section> with a <ul> where the list of key points will go. Then we have a <template> for the list items that has two <li> elements: one with a <slot> placeholder for the key points from the article and another with a centered design.
The layout is arbitrary. What’s important is placing a <slot> where the extracted key points will go. Whatever’s inside the <template> will not be rendered on the page until we add it to the page using script.
Further, the markup inside <template> can be styled using inline styles, or CSS enclosed by <style>:
<template id='keyPointsTemplate'>
<li><slot name='keyPoints'></slot></li>
<li style="text-align: center;">⤙—⤚</li>
<style>
li{/* Some style */}
</style>
</template>The fun part! Let’s pick the key points from the article. Notice the value of the name attribute for the <slot> inside the <template> (keyPoints) because we’ll need that.
<article>
<h1>Bears</h1>
<p>Bears are carnivoran mammals of the family Ursidae. <span><span slot='keyPoints'>They are classified as caniforms, or doglike carnivorans</span></span>. Although only eight species of bears <!-- more content --> and partially in the Southern Hemisphere. <span><span slot='keyPoints'>Bears are found on the continents of North America, South America, Europe, and Asia</span></span>.<!-- more content --></p>
<p>While the polar bear is mostly carnivorous, <!-- more content -->. Bears use shelters, such as caves and logs, as their dens; <span><span slot='keyPoints'>Most species occupy their dens during the winter for a long period of hibernation</span></span>, up to 100 days.</p>
<!-- More paragraphs -->
</article>The key points are wrapped in a <span> carrying a slot attribute value (“keyPoints“) matching the name of the <slot> placeholder inside the <template>.
Notice, too, that I’ve added another outer <span> wrapping the key points.
The reason is that slot names are usually unique and are not repeated, because one <slot> matches one element using one slot name. If there’re more than one element with the same slot name, the <slot> placeholder will be replaced by all those elements consecutively, ending in the last element being the final content at the placeholder.
So, if we matched that one single <slot> inside the <template> against all of the <span> elements with the same slot attribute value (our key points) in a paragraph or the whole article, we’d end up with only the last key point present in the paragraph or the article in place of the <slot>.
That’s not what we need. We need to show all the key points. So, we’re wrapping the key points with an outer <span> to match each of those individual key points separately with the <slot>. This is much more obvious by looking at the script, so let’s do that.
const keyPointsTemplate = document.querySelector('#keyPointsTemplate').content;
const keyPointsSection = document.querySelector('#keyPointsSection > ul');
/* Loop through elements with 'slot' attribute */
document.querySelectorAll('[slot]').forEach((slot)=>{
let span = slot.parentNode.cloneNode(true);
span.attachShadow({ mode: 'closed' }).appendChild(keyPointsTemplate.cloneNode(true));
keyPointsSection.appendChild(span);
});First, we loop through every <span> with a slot attribute and get a copy of its parent (the outer <span>). Note that we could also loop through the outer <span> directly if we’d like, by giving them a common class value.
The outer <span> copy is then attached with a shadow tree (span.attachShadow) made up of a clone of the template’s content (keyPointsTemplate.cloneNode(true)).
This “attachment” causes the <slot> inside the template’s list item in the shadow tree to absorb the inner <span> carrying its matching slot name, i.e. our key point.
The slotted key point is then added to the key points section at the end of the page (keyPointsSection.appendChild(span)).
This happens with all the key points in the course of the loop.
That’s really about it. We’ve snagged all of the key points in the article, made copies of them, then dropped the copies into the list template so that all of the key points are grouped together providing a nice little CliffsNotes-like summary of the article.
Here’s that demo once again:
See the Pen
Text Extraction with HTML Slot and HTML Template by Preethi Sam (@rpsthecoder)
on CodePen.
What do you think of this technique? Is it something that would be useful in long-form content, like blog posts, news articles, or even Wikipedia entries? What other use cases can you think of?
This is an interesting concept. I could see it being used with the HTML
markelement to highlight the key points in the text. (I could even see an interactive feature that allows the reader to highlight whatever passages they feel are the key points, and then display those passages at the end of the article for easy reference and/or printing.)Concept aside, I still don’t understand why you need the outer
spans. Since you’re building the key points list via JavaScript, you can clone whatever elements you want.document.querySelectorAll('[slot]')will find all of the innerspans (the ones with the “slot” attribute), and you’ll clone those (one at a time), attaching a clone of the template (which I’m assuming you can clone as many times as you need to) and then appending the result to theul. So I guess I don’t understand your statement about the named slot (in the template, I assume) normally being overwritten by each element with that same slot name. When I read that I assumed the slot in the template was filled automatically by the browser’s HTML engine, but that doesn’t seem to be the case since you’ve used JavaScript to generate the list of key points. Can you explain what I’m missing?One other nit to pick: you seem to care about semantics, but you’re using
lielements for purely decorative purposes. For accessibility reasons* you should at least includerole="presentation"on those “separator”lis, so a screen reader would not include them when it announces (a) how many items are in the list and (b) the list items themselves. Better yet would be to eliminate them altogether and use CSS to display those separators.(*I realize this article isn’t focused on accessibility, but I feel it’s always worthwhile to demonstrate best practices in any tutorial—even when those practices aren’t the main focus of the article.)
All that said, thanks for giving me a new technique to explore!